Benchmark for Bzip2
Source
linux-kernel tarball 628MB(658,053,120 bytes) for Huffman coding
500MB random data(for worse situation and Burrows–Wheeler transform)
generate by dd if=/dev/urandom of=test.500mb bs=1M count=500
Platform
Arch64 and x84_64
Modify the Makefile compiler flag with -pg
Compile the source, so we can profiling it
On AArch64
500MB random data with best flag(-9)
real 16m50.237s
user 16m48.650s
sys 0m1.520s
On X84_64
linux-kernel tarball with best flag(-9)
real 1m39.944s
user 1m39.464s
sys 0m0.388s
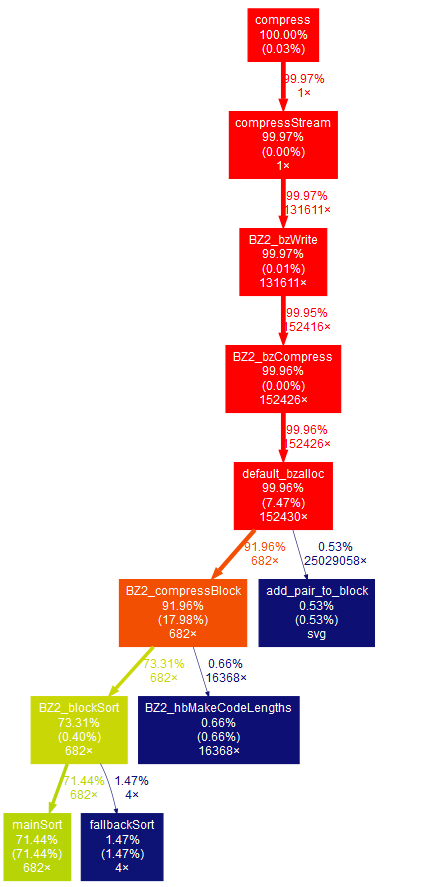
500MB random data with best flag(-9)
real 1m58.764s
user 1m57.768s
sys 0m0.889s

It looks like we can find possible optimization in mainSort in blocksort.c(27.32%) and BZ2_compressBlock in compress.c(38.61%)
There is possible to find tiny optimization in huffman.c
Possible Optimization
Remove the for loop to reduce branch
1.mainsort function in blocksort.c Line 769
/*– set up the 2-byte frequency table –*/
for (i = 65536; i >= 0; i–) ftab[i] = 0;
Optimization:
memset(&ftab[0],0,65537*sizeof(int)); // not working when int has 4byte
2.Loop Unroll
add -funroll-loops flag as compiler option (it will increase the size of file)
