HTML:
</div>
</div>
CSS:
#wrap {
perspective:500px;
transform:translateY(200px);
}
#cube{
transform-style:preserve-3d;
}
.face{
margin-left:-100px;
margin-top:-100px;
top:50%;
left:50%;
position:absolute;
height:200px;
width:200px;
background-color:sandybrown;
line-height:200px;
border:2px solid black;
text-align:center;
font-size:150px;
opacity:0.5;
}
.face:first-child{
transform:translateZ(100px);
}
.face:nth-child(2){
transform:translateZ(-100px) rotateY(180deg);
}
.face:nth-child(3){
transform:translateX(-100px) rotateY(-90deg);
}
.face:nth-child(4){
transform:translateX(100px) rotateY(90deg);
}
.face:nth-child(5){
transform:translateY(-100px) rotateX(90deg);
}
.face:nth-child(6){
transform:translateY(100px) rotateX(-90deg);
}
#cube:nth-child(n){
animation-name:cube;
animation-duration:4s;
animation-iteration-count:infinite;
}
@keyframes cube{
from{transform:rotate3d(0,0,0,0deg)}
to{transform:rotate3d(1,1,1,360deg);}
}
There is two way to optimize the bzip2 compression time.
In the mainsort function of blocksort.c
- Using memset() function instead a for loop to set each elements in an array to zero. By doing this, it will reduce the memory usage by using shared library, and reduce the branch amount from the for loop.
-for (i = 65536; i >= 0; i–) ftab[i] = 0;
+memset(&ftab[0],0,65537*sizeof(Int32));
2.Manually unroll the loop it will increase the run time memory usage, as the author said it will produced wrong code while compile with gcc 2.7.x.
It will reduce the branch of the program, which will reduce the compression time.
– //for (i = 1; i <= 65536; i++) ftab[i] += ftab[i-1]
+for (i = 1; i<= 65536; i+=8){
+ ftab[i] += ftab[i-1];
+ ftab[i+1] += ftab[i];
+ ftab[i+2] += ftab[i+1];
+ ftab[i+3] += ftab[i+2];
+ ftab[i+4] += ftab[i+3];
+ ftab[i+5] += ftab[i+4];
+ ftab[i+6] += ftab[i+5];
+ ftab[i+7] += ftab[i+6];
+ }
After compile the program, it passed 6 tests from its own on x86_64 and AArch64 machine.
Doing 6 tests (3 compress, 3 uncompress) …
If there’s a problem, things might stop at this point.
./bzip2 -1 < sample1.ref > sample1.rb2
./bzip2 -2 < sample2.ref > sample2.rb2
./bzip2 -3 < sample3.ref > sample3.rb2
./bzip2 -d < sample1.bz2 > sample1.tst
./bzip2 -d < sample2.bz2 > sample2.tst
./bzip2 -ds < sample3.bz2 > sample3.tst
cmp sample1.bz2 sample1.rb2
cmp sample2.bz2 sample2.rb2
cmp sample3.bz2 sample3.rb2
cmp sample1.tst sample1.ref
cmp sample2.tst sample2.ref
cmp sample3.tst sample3.ref
If you got this far and the ‘cmp’s didn’t complain, it looks
like you’re in business.
On x86_64 machine, while compression the linux-kernel tarball(version 4.5) with 628MB(658,053,120 bytes)
The compression time before
real 1m39.944s
user 1m39.464s
sys 0m0.388s
The compression time after
real 1m27.951s
user 1m27.428s
sys 0m0.443s
After running the cmp between the file compressed before and after, it was the same file
It reduced the compression by nearly 12% from the previous version
On AArch64 machine, while compression the linux-kernel tarball(version 4.5) with 628MB(658,053,120 bytes)
The compression time before
real 13m32.371s
user 13m29.980s
sys 0m1.890s
The compression time after
real 11m59.926s
user 11m58.790s
sys 0m0.960s
After running the cmp between the file compressed before and after, it was the same file
It reduced the compression time by nearly 11.5% from the previous version
Benchmark for Bzip2
Source
linux-kernel tarball 628MB(658,053,120 bytes) for Huffman coding
500MB random data(for worse situation and Burrows–Wheeler transform)
generate by dd if=/dev/urandom of=test.500mb bs=1M count=500
Platform
Arch64 and x84_64
Modify the Makefile compiler flag with -pg
Compile the source, so we can profiling it
On AArch64
500MB random data with best flag(-9)
real 16m50.237s
user 16m48.650s
sys 0m1.520s
On X84_64
linux-kernel tarball with best flag(-9)
real 1m39.944s
user 1m39.464s
sys 0m0.388s
500MB random data with best flag(-9)
real 1m58.764s
user 1m57.768s
sys 0m0.889s

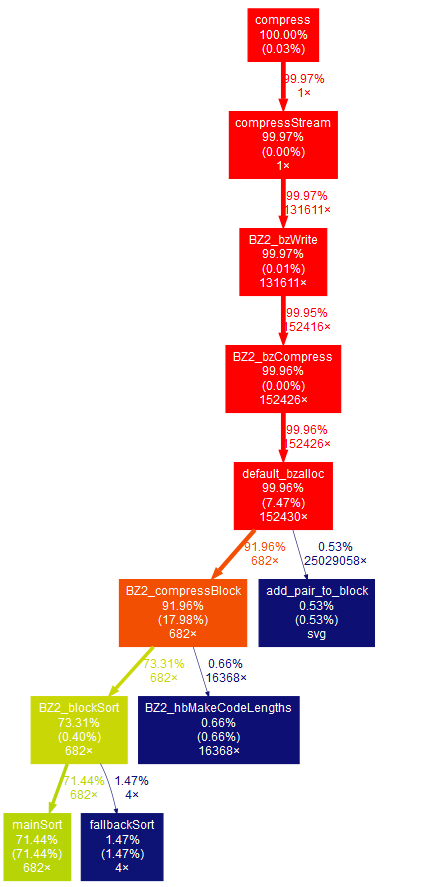
It looks like we can find possible optimization in mainSort in blocksort.c(27.32%) and BZ2_compressBlock in compress.c(38.61%)
There is possible to find tiny optimization in huffman.c
Possible Optimization
Remove the for loop to reduce branch
1.mainsort function in blocksort.c Line 769
/*– set up the 2-byte frequency table –*/
for (i = 65536; i >= 0; i–) ftab[i] = 0;
Optimization:
memset(&ftab[0],0,65537*sizeof(int)); // not working when int has 4byte
2.Loop Unroll
add -funroll-loops flag as compiler option (it will increase the size of file)
In this lab, using a simple Hello World Program to demonstrate the 3 different
GCC compiler options and the way it optimize the code in x84_64 enviroment:
Hello World:
#include <stdio.h>
int main() {
printf(“Hello World!\n”);
}
GCC Compile Option:
-g # enable debugging information
-O0 # do not optimize (that’s a capital letter and then the digit zero)
-fno-builtin # do not use builtin function optimizations
(1)GCC -g -O0 -fno-builtin -o: this is the original used to compare with others
Size: 9,536byte
0000000000400536 <main>:
#include <stdio.h>
int main() {
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
printf(“Hello World!\n”);
40053a: bf e0 05 40 00 mov $0x4005e0,%edi
40053f: b8 00 00 00 00 mov $0x0,%eax
400544: e8 c7 fe ff ff callq 400410 <printf@plt>
400549: b8 00 00 00 00 mov $0x0,%eax
}
40054e: 5d pop %rbp
40054f: c3 retq
0000000000400410 <printf@plt>:
400410: ff 25 02 0c 20 00 jmpq *0x200c02(%rip) # 601018 <_GLOBAL_OFFSET_TABLE_+0x18 >
400416: 68 00 00 00 00 pushq $0x0
40041b: e9 e0 ff ff ff jmpq 400400 <_init+0x20>
(2)GCC -g -O0 -fno-builtin -static -o : Add the compiler option -static
Size: 855,736byte
With the -static option it will including all the stdio library file (no only the function used for the hello world program)
as static memory, which will make the file size extremely large than the original version.
The difference between the original version and static version are highlight with red.
It using _IO_prinft function call instead of printf@plt funciton call.
And also have one additional operation ‘nopl’ which is one-byte ‘do nothing’ operation.
000000000040095e <main>:
40095e: 55 push %rbp
40095f: 48 89 e5 mov %rsp,%rbp
400962: bf 10 77 49 00 mov $0x497710,%edi
400967: b8 00 00 00 00 mov $0x0,%eax
40096c: e8 3f 0b 00 00 callq 4014b0 <_IO_printf>
400971: b8 00 00 00 00 mov $0x0,%eax
400976: 5d pop %rbp
400977: c3 retq
400978: 0f 1f 84 00 00 00 00 nopl 0x0(%rax,%rax,1)
40097f: 00
Here is the _IO_printf, not like the printf@plt in the original version,
it representing the whole scenario of display
on the screen. On the original version, the printf@plt will jump to the actual display function in the dynamic linked library.
00000000004014b0 <_IO_printf>:
4014b0: 48 81 ec d8 00 00 00 sub $0xd8,%rsp
4014b7: 84 c0 test %al,%al
4014b9: 48 89 74 24 28 mov %rsi,0x28(%rsp)
4014be: 48 89 54 24 30 mov %rdx,0x30(%rsp)
4014c3: 48 89 4c 24 38 mov %rcx,0x38(%rsp)
4014c8: 4c 89 44 24 40 mov %r8,0x40(%rsp)
4014cd: 4c 89 4c 24 48 mov %r9,0x48(%rsp)
4014d2: 74 37 je 40150b <_IO_printf+0x5b>
4014d4: 0f 29 44 24 50 movaps %xmm0,0x50(%rsp)
4014d9: 0f 29 4c 24 60 movaps %xmm1,0x60(%rsp)
4014de: 0f 29 54 24 70 movaps %xmm2,0x70(%rsp)
4014e3: 0f 29 9c 24 80 00 00 movaps %xmm3,0x80(%rsp)
4014ea: 00
4014eb: 0f 29 a4 24 90 00 00 movaps %xmm4,0x90(%rsp)
4014f2: 00
4014f3: 0f 29 ac 24 a0 00 00 movaps %xmm5,0xa0(%rsp)
4014fa: 00
4014fb: 0f 29 b4 24 b0 00 00 movaps %xmm6,0xb0(%rsp)
401502: 00
401503: 0f 29 bc 24 c0 00 00 movaps %xmm7,0xc0(%rsp)
40150a: 00
40150b: 48 8d 84 24 e0 00 00 lea 0xe0(%rsp),%rax
401512: 00
401513: 48 89 fe mov %rdi,%rsi
401516: 48 8d 54 24 08 lea 0x8(%rsp),%rdx
40151b: 48 8b 3d 7e bb 2b 00 mov 0x2bbb7e(%rip),%rdi # 6bd0a0 <_IO_stdout>
401522: 48 89 44 24 10 mov %rax,0x10(%rsp)
401527: 48 8d 44 24 20 lea 0x20(%rsp),%rax
40152c: c7 44 24 08 08 00 00 movl $0x8,0x8(%rsp)
401533: 00
401534: c7 44 24 0c 30 00 00 movl $0x30,0xc(%rsp)
40153b: 00
40153c: 48 89 44 24 18 mov %rax,0x18(%rsp)
401541: e8 fa 41 01 00 callq 415740 <_IO_vfprintf>
401546: 48 81 c4 d8 00 00 00 add $0xd8,%rsp
40154d: c3 retq
40154e: 66 90 xchg %ax,%ax
(3)GCC -g -O0 -o : Remove the compiler option -fno-builtin
Without the -fno-builtin option, GCC compiler will using builtin function to optimize the code.
The difference between original version and function builtin version is highlight with red.
It using puts@plt instead of printf@plt.
0000000000400536 <main>:
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: bf e0 05 40 00 mov $0x4005e0,%edi
40053f: e8 cc fe ff ff callq 400410 <puts@plt>
400544: b8 00 00 00 00 mov $0x0,%eax
400549: 5d pop %rbp
40054a: c3 retq
40054b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
The functionality between puts@plt and printf@plt is same when we only have one pramater on printf function call.
If we have more than one pramater, the GCC compiler will using printf@plt in both situation.
0000000000400410 <puts@plt>:
400410: ff 25 02 0c 20 00 jmpq *0x200c02(%rip) # 601018 <_GLOBAL_OFFSET_TABLE_+0x18>
400416: 68 00 00 00 00 pushq $0x0
40041b: e9 e0 ff ff ff jmpq 400400 <_init+0x20>
puts is a straight forward function call to display string on the screen,
while the printf will scan the pramater and ‘%’ to determine the output, which will taking extra time to performance.
(4)GCC -O0 -fno-builtin -o : Remove the compiler option -g
Size:8504byte
The difference between original version and no debug information version is highlight with red.
Because it will not include the debugging information without option -g, the total file size was reduced.
0000000000400536 <main>:
#include <stdio.h>
int main() {
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
printf(“Hello World!\n”);
40053a: bf e0 05 40 00 mov $0x4005e0,%edi
40053f: b8 00 00 00 00 mov $0x0,%eax
400544: e8 c7 fe ff ff callq 400410 <printf@plt>
400549: b8 00 00 00 00 mov $0x0,%eax
}
40054e: 5d pop %rbp
40054f: c3 retq
(5)GCC -g -O0 -fno-builtin -o : Add additional arguments to the printf()
#include <stdio.h>
int main() {
int a=10,b=20,c=30,d=40,e=50,f=60,g=70,h=80,i=90,j=100;
printf(“Hello World!\n%d %d %d %d %d %d %d %d %d %d”,a,b,c,d,e,f,g,h,i,j);
}
The first five value declare in the Hello World program move into five different register %eax,%edx,%ecx,%edi,%r8d
The last five value declare in the Hello World program move to the register %esi and push to the stack.
0000000000400536 <main>:
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: 48 83 ec 30 sub $0x30,%rsp
40053e: c7 45 fc 0a 00 00 00 movl $0xa,-0x4(%rbp)
400545: c7 45 f8 14 00 00 00 movl $0x14,-0x8(%rbp)
40054c: c7 45 f4 1e 00 00 00 movl $0x1e,-0xc(%rbp)
400553: c7 45 f0 28 00 00 00 movl $0x28,-0x10(%rbp)
40055a: c7 45 ec 32 00 00 00 movl $0x32,-0x14(%rbp)
400561: c7 45 e8 3c 00 00 00 movl $0x3c,-0x18(%rbp)
400568: c7 45 e4 46 00 00 00 movl $0x46,-0x1c(%rbp)
40056f: c7 45 e0 50 00 00 00 movl $0x50,-0x20(%rbp)
400576: c7 45 dc 5a 00 00 00 movl $0x5a,-0x24(%rbp)
40057d: c7 45 d8 64 00 00 00 movl $0x64,-0x28(%rbp)
400584: 44 8b 45 ec mov -0x14(%rbp),%r8d
400588: 8b 7d f0 mov -0x10(%rbp),%edi
40058b: 8b 4d f4 mov -0xc(%rbp),%ecx
40058e: 8b 55 f8 mov -0x8(%rbp),%edx
400591: 8b 45 fc mov -0x4(%rbp),%eax
400594: 48 83 ec 08 sub $0x8,%rsp
400598: 8b 75 d8 mov -0x28(%rbp),%esi
40059b: 56 push %rsi
40059c: 8b 75 dc mov -0x24(%rbp),%esi
40059f: 56 push %rsi
4005a0: 8b 75 e0 mov -0x20(%rbp),%esi
4005a3: 56 push %rsi
4005a4: 8b 75 e4 mov -0x1c(%rbp),%esi
4005a7: 56 push %rsi
4005a8: 8b 75 e8 mov -0x18(%rbp),%esi
4005ab: 56 push %rsi
4005ac: 45 89 c1 mov %r8d,%r9d
4005af: 41 89 f8 mov %edi,%r8d
4005b2: 89 c6 mov %eax,%esi
4005b4: bf 60 06 40 00 mov $0x400660,%edi
4005b9: b8 00 00 00 00 mov $0x0,%eax
4005be: e8 4d fe ff ff callq 400410 <printf@plt>
4005c3: 48 83 c4 30 add $0x30,%rsp
4005c7: b8 00 00 00 00 mov $0x0,%eax
4005cc: c9 leaveq
4005cd: c3 retq
4005ce: 66 90 xchg %ax,%ax
(6)GCC -g -O0 -fno-builtin -o : Move the printf() call to a sepraate funciton name output()
#include <stdio.h>
void output(){
printf(“Hello World!\n”);
}
int main() {
output();
}
The program call output from main and call printf@plt
from output and move $0x0 to %eax to empty the register before each function call.
000000000040054c <main>:
40054c: 55 push %rbp
40054d: 48 89 e5 mov %rsp,%rbp
400550: b8 00 00 00 00 mov $0x0,%eax
400555: e8 dc ff ff ff callq 400536 <output>
40055a: b8 00 00 00 00 mov $0x0,%eax
40055f: 5d pop %rbp
400560: c3 retq
400561: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
400568: 00 00 00
40056b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
0000000000400536 <output>:
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: bf 00 06 40 00 mov $0x400600,%edi
40053f: b8 00 00 00 00 mov $0x0,%eax
400544: e8 c7 fe ff ff callq 400410 <printf@plt>
400549: 90 nop
40054a: 5d pop %rbp
40054b: c3 retq>
(7)GCC -g -O3 -fno-builtin -o : Change -O0 to -O3
The compiler remove the first two line initialize code and did not go back
to main when the printf@plt function called as the last step of the Hello World program.
Original one:
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: bf e0 05 40 00 mov $0x4005e0,%edi
40053f: b8 00 00 00 00 mov $0x0,%eax
400544: e8 c7 fe ff ff callq 400410 <printf@plt>
400549: b8 00 00 00 00 mov $0x0,%eax
40054e: 5d pop %rbp
40054f: c3 retq
0000000000400440 <main>:
400440: 48 83 ec 08 sub $0x8,%rsp
400444: bf f0 05 40 00 mov $0x4005f0,%edi
400449: 31 c0 xor %eax,%eax
40044b: e8 c0 ff ff ff callq 400410 <printf@plt>
400450: 31 c0 xor %eax,%eax
400452: 48 83 c4 08 add $0x8,%rsp
400456: c3 retq
400457: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
40045e: 00 00
This is the first time I step into assembly language which is so differently than other programming language I had learned. In this lab, we build a simple loop program to get our feet wet on both AArch64 and x86_64 enviroment.
The lab required us to build a simple loop program to display as below:
Loop: 0
Loop: 1
Loop: 2
Loop: 3
Loop: 4
Loop: 5
Loop: 6
Loop: 7
Loop: 8
Loop: 9
Loop:10
and so on
Here is the code writing on x86_64.
.text
.globl _start
start = 0 /* starting value for the loop index; note that this is a symbol (constant), not a variable */
max = 31 /* loop exits when the index hits this number (loop condition is i<max) */
_start:
mov $start,%r15 /* loop index */
mov $10,%r10
loop:
/* … body of the loop … do something useful here … */
mov %r15,%rax
mov $0,%rdx
div %r10
cmp $0,%rax
je onedigit
mov %rax,%r14
add $48,%r14
onedigit:
mov %rdx,%r13
add $48,%r13
movb %r14b,msg+5
movb %r13b,msg+6
mov $len,%rdx
mov $msg,%rsi
mov $1,%rdi
mov $1,%rax
syscall
inc %r15 /* increment index */
cmp $max,%r15 /* see if we’re done */
jne loop /* loop if we’re not */
mov $0,%rdi /* exit status */
mov $60,%rax /* syscall sys_exit */
syscall
.data
msg: .ascii “Loop: \n”
.set len , . – msg
In this code, the method that convert value to ASCII character are highlight with red, the method that converting 2-digit number was highlight with blue, the method to suppress high digit 0 was highlight with purple, and the method to replacing number in the Loop: string was highlight with green.
Here is the code writing on aarch64 with similar logic:
.text
.globl _start
start = 0 /* starting value for the loop index; note that this is a symbol (constant), not a variable */
max = 31 /* loop exits when the index hits this number (loop condition is i<max) */
_start:
mov x3,start /* loop index */
mov x10,10
loop:
adr x11,msg
/* … body of the loop … do something useful here … */
udiv x4,x3,x10
msub x5,x10,x4,x3
cmp x4,0
b.eq onedigit
add x4,x4,48
onedigit:
add x5,x5,48
strb w4,[x11,5]
strb w5,[x11,6]
mov x0,1
adr x1,msg
mov x2,len
mov x8,64
svc 0
add x3,x3,1 /* increment index */
cmp x3,max /* see if we’re done */
b.lt loop /* loop if we’re not */
mov x0,0 /* exit status */
mov x8,93 /* syscall sys_exit */
svc 0
.data
msg: .ascii “Loop: \n”
len= . – msg
In this code, the method that convert value to ASCII character are highlight with red, the method that converting 2-digit number was highlight with blue, the method to suppress high digit 0 was highlight with purple, and the method to replacing number in the Loop: string was highlight with green.
Because the syntax are totally different between aarch64 and x84_64, the method is looks like different, but the logic behind the code is same.
